![]()
OpenAI’s upcoming artificial intelligence model will deliver smaller performance gains than its predecessors, sources familiar with the matter said The information.
Employee testing shows Orion achieved GPT-4 level performance after completing just 20% of the training, The Information reports.
The quality increase from GPT-4 to the current version of GPT-5 seems smaller than that from GPT-3 to GPT-4.
“Some researchers at the company believe that Orion is not reliably better than its predecessor at performing certain tasks, the (OpenAI) staff said,” The Information reported. “Orion performs better on language tasks, but may not outperform previous models on tasks like coding, an OpenAI official said.”
While Orion getting closer to GPT-4 with 20% of its training may sound impressive to some, it’s important to note that the early stages of AI training typically yield the most dramatic improvements, while subsequent stages yield smaller gains .
So the remaining 80% of training time is unlikely to yield the same level of progress as previous generational leaps, sources said.
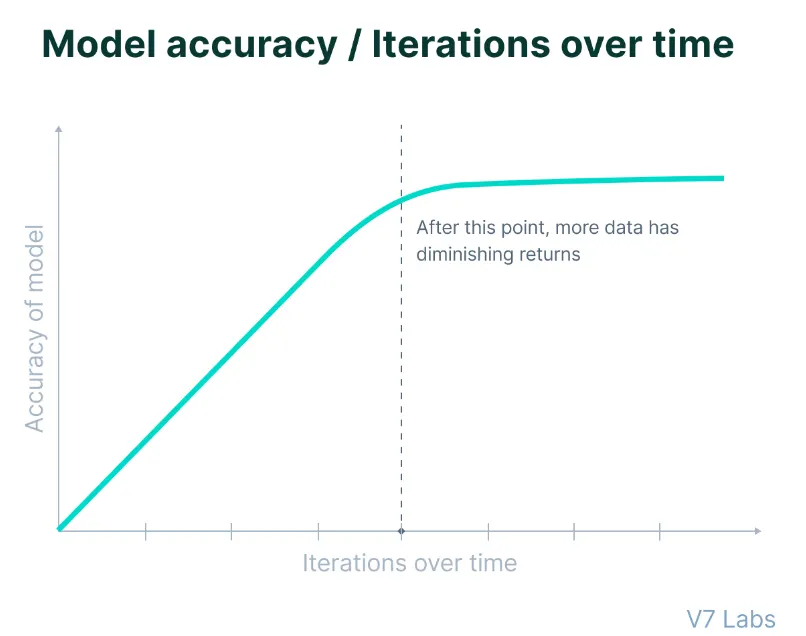 Image: V7 laboratories
Image: V7 laboratories
The restrictions come at a crucial time for OpenAI following its recent $6.6 billion funding round.
The company now faces higher expectations from investors as it grapples with technical limitations that challenge traditional scaling approaches in AI development. If these early versions don’t live up to expectations, the company’s upcoming fundraising efforts may not be met with the same hype as before — and that could be a problem for a potentially for-profit company, which is what Sam Altman says. seems to want for Open AI.
Disappointing results point to a fundamental challenge facing the entire AI industry: the dwindling supply of high-quality training data and the need to stay relevant in a field as competitive as generative AI.
Research published in June predicted that AI companies will deplete available public human-generated text data between 2026 and 2032, marking a crucial turning point for traditional development approaches.
“Our findings indicate that current LLM development trends cannot be sustained by conventional data scaling alone,” said the research paper States, highlighting the need for alternative approaches to model improvement, including generating synthetic data, transferring learning from data-rich domains, and using non-public data.
The historic strategy of training language models on publicly available text from websites, books and other sources has reached a point of diminishing returns, with developers “largely squeezing as much as they can out of that kind of data,” according to The Information. .
How OpenAI tackles this problem: reasoning versus language models
To address these challenges, OpenAI is fundamentally restructuring its approach to AI development.
“In response to the recent challenge to training-based scaling laws arising from slowing GPT improvements, the industry appears to be shifting its efforts to improving models after their initial training, potentially yielding a different kind of scaling law,” reports The Information.
To achieve this state of continuous improvement, OpenAI divides model development into two separate tracks:
The O-series (which appears to be codenamed Strawberry), focused on reasoning skills, represents a new direction in model architecture. These models operate at a significantly higher computational intensity and are explicitly designed for complex problem-solving tasks.
The computational requirements are significant, with early estimates pointing to operating costs six times that of current models. However, the improved reasoning capabilities could justify the higher cost for specific applications that require advanced analytical processing.
This model, if it is the same as Strawberry, is also tasked with generating enough synthetic data to continuously increase the quality of OpenAI’s LLMs.
At the same time, the Orion models or the GPT series (given OpenAI trademarked the name GPT-5) continue to evolve, focusing on general language processing and communication tasks. These models maintain more efficient computing requirements while leveraging their broader knowledge base for writing and argumentation tasks.
OpenAI’s CPO Kevin Weil does too confirmed this during an AMA and said that he expects both developments to converge at some point in the future.
“It’s not either or, it’s both,” he responded when asked whether OpenAI would focus on scaling LLMs with more data or take a different approach, focusing on smaller but faster models, “better base models plus more strawberry scaling/inference time calculation. ”
A workaround or the ultimate solution?
OpenAI’s approach to addressing data scarcity through synthetic data generation poses complex challenges for the industry. The company’s researchers develop advanced models designed to generate training data, but this solution introduces new complications in maintaining model quality and reliability.
As before reported Through Declutterresearchers have discovered that model training on synthetic data is a double-edged sword. While it provides a potential solution to data scarcity, it introduces new risks of model degradation and reliability issues with proven degradation after several training iterations.
In other words, as models train on AI-generated content, they can begin to amplify subtle imperfections in their results. These feedback loops can perpetuate and magnify existing biases, creating a compound effect that is increasingly difficult to detect and correct.
OpenAI’s Foundations team is developing new filtering mechanisms to maintain data quality and implementing various validation techniques to distinguish between high-quality and potentially problematic synthetic content. The team is also exploring hybrid training approaches that strategically combine human and AI-generated content to maximize the benefits of both sources while minimizing their respective drawbacks.
Post-training optimization has also gained relevance. Researchers are developing new methods to improve model performance after the initial training phase, potentially providing a way to improve capabilities without relying solely on expanding the training dataset.
That said, GPT-5 is still an embryo of a complete model with significant development work ahead. Sam Altman, CEO of OpenAI, has indicated that it won’t be ready for deployment this year or next. This extended timeline could be beneficial, allowing researchers to address current limitations and potentially discover new methods for model improvement, significantly improving GPT-5 before its eventual release.
Edited by Josh Quittner And Sebastian Sinclair
Generally intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.
Leave a Reply